Evaluates Data Filter Rules for foehnix Mixture Moel Calls
Source:R/foehnix_filter.R
foehnix_filter.Rdfoehnix models allow to specify an optional
foehnix_filter. If a filter is given only a subset
of the data set provided to foehnix is used
for the foehn classification.
A typical example is a wind direction filter such that
only observations (times) are used where the observed
wind direction was within a user defined wind sector
corresponding to the wind direction during foehn events
for a specific location.
However, the filter option allows to even implement complex
filter rules if required. The 'Details' section contains
further information and examples how this filter rules can
be used.
foehnix_filter(x, filter, cols = NULL)
# S3 method for class 'foehnix.filter'
print(x, ...)Arguments
- x
object of class
zooordata.framecontaining the observations.- filter
can be
NULL(no filter applied), a function operating onx, or a named list with a simple filter rule (numericof length two) or custom filter functions. Details provided in the 'Details' section.- cols
NULLor a character vector containing the names in 'x' which are not allowed to contain missing values. IfNULLall elements have to be non-missing.- ...
currently unused.
Value
Returns a vector of integers corresponding to those rows in
the data set x which fulfill all filte criteria. If input
filter = NULL an integer vector 1:nrow(x) is returned.
Details
Foehn winds often (not always) show a very specific wind direction
due to the canalization of the air flow trough the local topography. The
foehnix_filter option allows to subset the data according to a
user defined set of filters from simple filters to complex filters.
These filters classify each observation (each row in x) as
good (within filter), bad (outside filter), and ugly (at least one
variable required to apply the filter was NA).
No filter: If filter = NULL no filter will be applied and the whole
data set provided is used to do the foehn classification (all observations
will be treated as 'good').
Simple filter rules: The filter is a named list containing one or several
numeric vectors of length 2 with finite numeric values. The name of the
list element defines the column of the data set (input x), the
numeric vector of length 2 the range which should be used to filter the
data. This is the simplest option to apply the mentioned wind direction
filter. Examples:
filter = list(dd = c(43, 223)): applies the filter to columnx$dd. The filter classifies observations/rows as 'good' (within filter) ifx$dd >= 43 & x$dd <= 223.filter = list(dd = c(330, 30): similar to the filter rule above, allows to specify a wind sector going trough 0 (if dd is wind direction in degrees between[0, 360]). The filter classifies observations/rows as 'good' (within filter) ifx$dd >= 330 | x$dd <= 30.filter = list(dd = c(43, 223), crest_dd = c(90, 270): two filter rules, one forx$dd, one forx$crest_dd. The filter classifies observations/rows as 'good' (within filter) ifx$dd >= 43 & x$dd <= 223ANDx$crest_dd >= 330 | x$crest_dd <= 30. If an observation/row does not fulfill one or the other rule the observation/row is classified as 'bad' (outside filter), if one ofx$ddorx$crest_ddisNAthe corresponding observation/row will be classified as 'ugly'.Filters are not restricted to wind direction (as shown in the examples above)!
Custom filter functions: Instead of only providing a segment/sector defined
by two finite numeric values (see 'Simple filter' above) a named list of
functions can be provided. These functions DO HAVE TO return a vector of
logical values (TRUE (good),FALSE (bad), or NA (ugly))
of length nrow{x}. If not, an error will be thrown. The function will
be applied to the column specified by the name of the list element. Some
examples:
filter = list(dd = function(x) x >= 43 & x <= 223): The function will be applied tox$dd. A vector withTRUE,FALSE, orNAis returned for each1:nrow{x}which takesNAifis.na(x$dd),TRUEifx$dd >= 43 & x$dd <= 223andFALSEelse. Thus, this filter is the very same as the first example in the 'Simple filter' section above.filter = list(ff = function(x) x > 2.0): Custom filter applied to columnx$ff. A vector withTRUE,FALSE, andNAis returned for each observation1:nrow{x}which takesNAifis.na(x$ff),TRUEifx$ff > 2.0, andFALSEelse.filter = list(ff = function(x) ..., dd = function(x) ...): two filter functions, one applied tox$ff, one tox$dd. Note that observations/rows will be classified as 'ugly' if one of the two filters returnsNA. If noNAis returned the observation is classified as 'good' if both returnTRUE, and as 'bad' (outside filter) if at least one returnsFALSE.
Complex filters: If filter is a function this filter function will be
applied to the full input object x. This allows to write functions of
any complexity. As an example:
filter = function(x) (x$dd >= 43 & x$dd <= 223) & x$ff >= 2.0: Inputxto the filter function is the object as provided to thefoehnix_filterfunction (x). Thus, the different columns of the object can be accessed directly trough their names (e.g.,x$dd,x$ff). A vector of lengthnrow(x)withTRUE,FALSE, andNAhas to be returned. Only those classified as 'good' (TRUE) will be used for classification.
Examples
# Loading example data set and conver to zoo time series
# time series object (station Ellboegen).
ellboegen <- demodata("ellboegen")
# Case 1:
# -----------------
# Filter for observations where the wind direction is
# within 100 - 260 (southerly flow):
idx_south <- foehnix_filter(ellboegen, list(dd = c(100, 260)))
print(idx_south)
#>
#> Foehnix Filter Object:
#> Call: foehnix_filter(x = ellboegen, filter = list(dd = c(100, 260)))
#> Total data set length: 105370
#> The good (within filter): 50072 (47.5 percent)
#> The bad (outside filter): 52576 (49.9 percent)
#> The ugly (NA; missing values): 2722 ( 2.6 percent)
# Same filter but for northerly flows, taking rows with
# wind direction observations (dd) smaller than 45 or
# larger than 315 degrees:
idx_north <- foehnix_filter(ellboegen, list(dd = c(315, 45)))
print(idx_north)
#>
#> Foehnix Filter Object:
#> Call: foehnix_filter(x = ellboegen, filter = list(dd = c(315, 45)))
#> Total data set length: 105370
#> The good (within filter): 18143 (17.2 percent)
#> The bad (outside filter): 84505 (80.2 percent)
#> The ugly (NA; missing values): 2722 ( 2.6 percent)
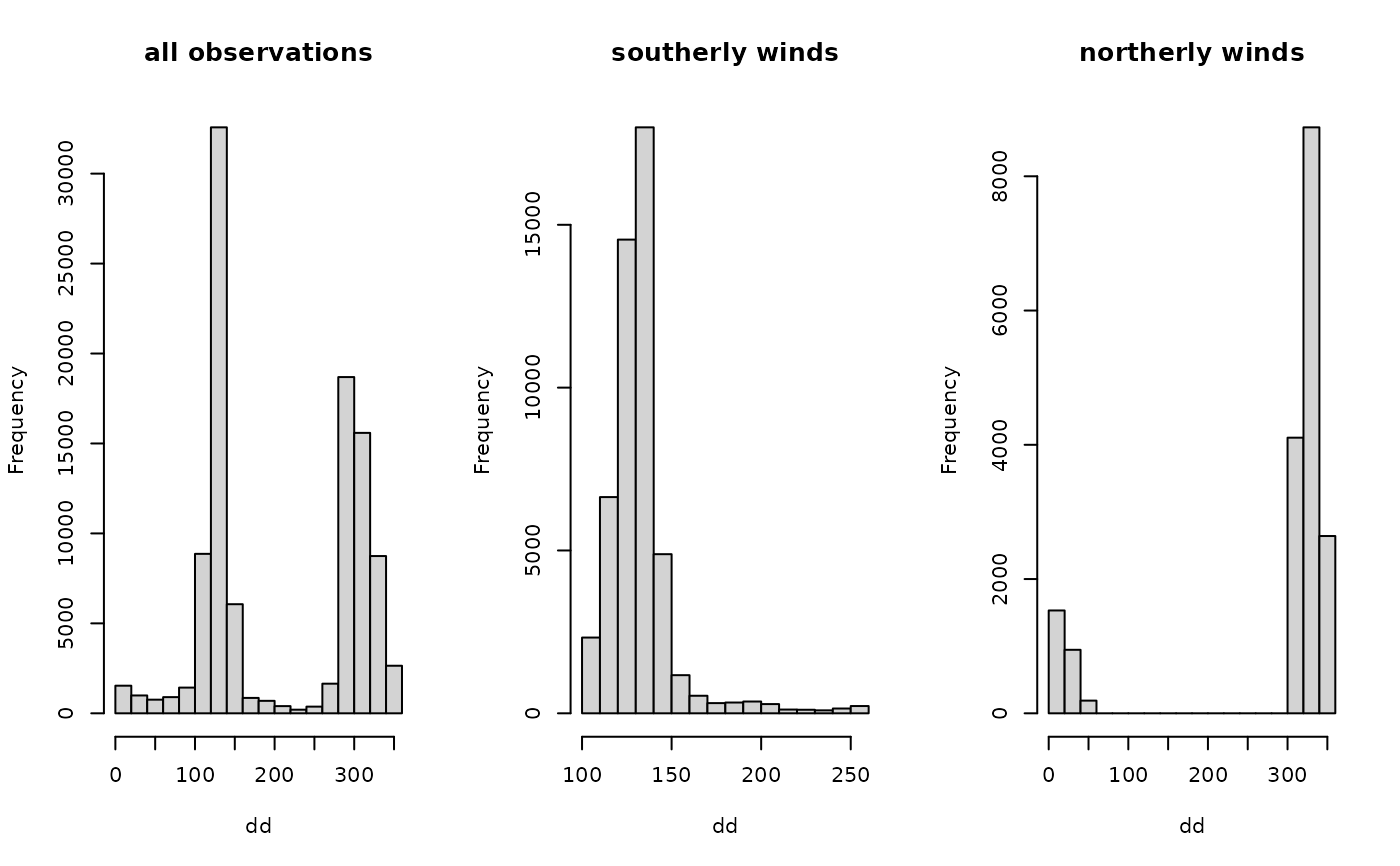
par(mfrow = c(1,3))
hist(ellboegen$dd, xlab = "dd", main = "all observations")
hist(ellboegen$dd[idx_south$good], xlab = "dd", main = "southerly winds")
hist(ellboegen$dd[idx_north$good], xlab = "dd", main = "northerly winds")
 # Case 2:
# -----------------
# A second useful option is to add two filters:
# the wind direction at the target station (here Ellboegen)
# has to be within c(43, 223), the wind direction at the
# corresponding crest station (upstream, crest of the European Alps)
# has to show southerly flows with a wind direction from
# 90 degrees (East) to 270 degrees (West).
# Loading combined demo data set
data <- demodata()
# Now apply a wind filter
my_filter <- list(dd = c(43, 223), crest_dd = c(90, 270))
filter_obj <- foehnix_filter(data, my_filter)
print(filter_obj)
#>
#> Foehnix Filter Object:
#> Call: foehnix_filter(x = data, filter = my_filter)
#> Total data set length: 108425
#> The good (within filter): 24236 (22.4 percent)
#> The bad (outside filter): 50538 (46.6 percent)
#> The ugly (NA; missing values): 33651 (31.0 percent)
# Subsetting the 'good' rows
data <- data[filter_obj$good,]
summary(subset(data, select = c(dd, crest_dd)))
#> Index dd crest_dd
#> Min. :2006-01-01 01:00:00 Min. : 43.0 Min. : 90
#> 1st Qu.:2008-05-24 03:45:00 1st Qu.:124.0 1st Qu.:176
#> Median :2011-03-03 22:30:00 Median :132.0 Median :181
#> Mean :2011-12-01 13:06:51 Mean :131.3 Mean :182
#> 3rd Qu.:2016-01-05 15:15:00 3rd Qu.:138.0 3rd Qu.:187
#> Max. :2018-12-24 05:00:00 Max. :223.0 Max. :270
# Case 2:
# -----------------
# A second useful option is to add two filters:
# the wind direction at the target station (here Ellboegen)
# has to be within c(43, 223), the wind direction at the
# corresponding crest station (upstream, crest of the European Alps)
# has to show southerly flows with a wind direction from
# 90 degrees (East) to 270 degrees (West).
# Loading combined demo data set
data <- demodata()
# Now apply a wind filter
my_filter <- list(dd = c(43, 223), crest_dd = c(90, 270))
filter_obj <- foehnix_filter(data, my_filter)
print(filter_obj)
#>
#> Foehnix Filter Object:
#> Call: foehnix_filter(x = data, filter = my_filter)
#> Total data set length: 108425
#> The good (within filter): 24236 (22.4 percent)
#> The bad (outside filter): 50538 (46.6 percent)
#> The ugly (NA; missing values): 33651 (31.0 percent)
# Subsetting the 'good' rows
data <- data[filter_obj$good,]
summary(subset(data, select = c(dd, crest_dd)))
#> Index dd crest_dd
#> Min. :2006-01-01 01:00:00 Min. : 43.0 Min. : 90
#> 1st Qu.:2008-05-24 03:45:00 1st Qu.:124.0 1st Qu.:176
#> Median :2011-03-03 22:30:00 Median :132.0 Median :181
#> Mean :2011-12-01 13:06:51 Mean :131.3 Mean :182
#> 3rd Qu.:2016-01-05 15:15:00 3rd Qu.:138.0 3rd Qu.:187
#> Max. :2018-12-24 05:00:00 Max. :223.0 Max. :270